  Knowledge Base
0-1 A B C D E F G H I J K L M N O P Q R S T U V W X Y Z Tips&Trick Knowledge Base
0-1 A B C D E F G H I J K L M N O P Q R S T U V W X Y Z Tips&Trick
Realtek High Definition Audio (Tutte le versioni)
(ATTENZIONE! Segnalato da NOD32 come sito poco attendibile)
High Definition Audio Codecs (Driver)
Router NETGEAR DG834GIT V4
Thread Ufficiale dal sito www.hwupgrade.it
RAID - Redundant Array of Independent Disks
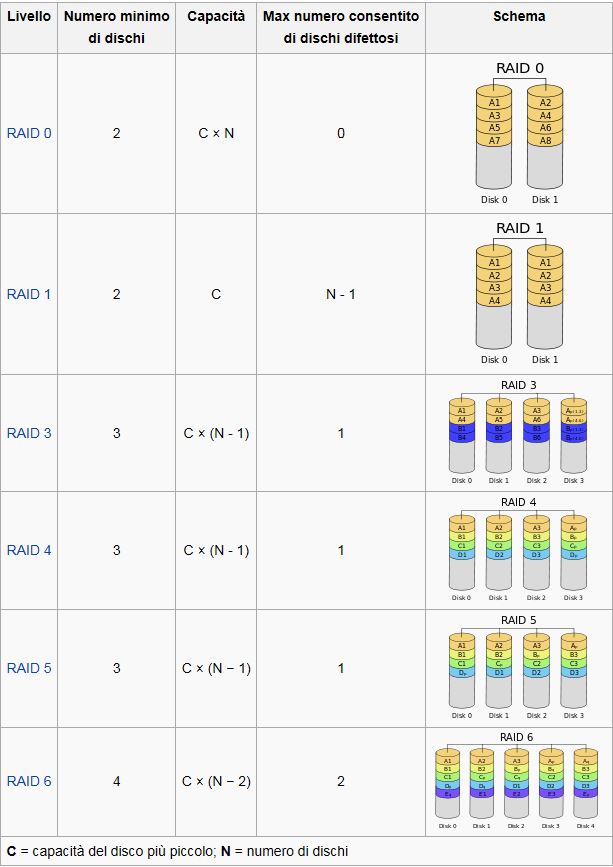
In informatica il RAID, acronimo di Redundant Array of Independent Disks, insieme ridondante di dischi indipendenti, e' una tecnica di
raggruppamento di diversi dischi rigidi collegati ad un computer che li rende utilizzabili, dalle applicazioni e dall'utente, come se fosse un unico
volume di memorizzazione. Tale aggregazione sfrutta, con modalita' differenti a seconda del tipo di implementazione, i principi di ridondanza dei
dati e di parallelismo nel loro accesso per garantire, rispetto ad un disco singolo, incrementi di prestazioni, aumenti nella capacita' di memorizzazione
disponibile, miglioramenti nella tolleranza ai guasti.
Il RAID e' una tecnica tipicamente impiegata nei server o nelle workstation che richiedano grandi volumi o elevate prestazioni di immagazzinamento
di dati, per esempio per ospitare una base di dati o una postazione di montaggio di audio o video digitali. Il RAID si trova comunemente anche nei NAS e,
sempre, nei sistemi di storage per architetture blade.
 RAID 0 (Striping)
Il sistema RAID 0 divide i dati equamente tra due o piu' dischi con nessuna informazione di parita' o ridondanza (operazione detta di
striping).
Bisogna notare che il RAID-0 non era presente tra i livelli RAID originari, e che non e' ridondante.
RAID-0 e' usato generalmente per aumentare le prestazioni di un sistema, anche se e' molto utile per creare un piccolo numero di grandi dischi
virtuali da un grande numero di piccoli dischi fisici.
Sebbene il RAID-0 non sia indicato tra i livelli RAID originari, in un sistema ideale di tipo RAID-0 le operazioni di I/O si dividerebbero in
blocchi di dimensioni uguali e si applicherebbero equamente su tutti i dischi.
Le implementazioni di sistemi RAID-0 su piu' di due dischi sono possibili, ma l'affidabilita' di un dato sistema RAID-0 e' uguale all'affidabilita'
media dei dischi diviso per il numero di dischi presenti. Quindi l'affidabilita', misurata come tempo medio tra due guasti (MTBF), e' inversamente
proporzionale al numero degli elementi; cioe' un sistema di due dischi e' affidabile la meta' di un disco solo.
La ragione per la quale questo succede è che il file system e' diviso tra tutti i dischi.
Quando un drive si guasta, il file system non puo' gestire una perdita di dati cosi' grande visto che i dati sono divisi tra tutti i dischi.
I dati possono essere spesso recuperati con qualche strumento, anche se saranno sicuramente incompleti e danneggiati.
RAID-0 e' molto utile per creare grandi server NFS in una sola posizione, nei casi nei quali montare molti dischi e' dispendioso o impossibile
e la ridondanza e' irrilevante.
Si usa anche quando il numero di dischi sia limitato dal sistema operativo. In Microsoft Windows, il numero delle lettere dei dischi e' limitato
a 128, cosi' il RAID-0 e' un modo molto diffuso per usare un numero maggiore di dischi. Comunque, siccome non c'e' ridondanza, i dati sono
condivisi tra i dischi e i dischi non possono essere sostituiti visto che sono tutti dipendenti tra di loro.
Questo tipo di progettazione non e' in realta' un vero e proprio RAID, in quanto non c'e' alcuna ridondanza
Vantaggi: costo economico di implementazione basso, alte prestazioni in scrittura e lettura (grazie al parallelismo delle operazioni I/O
dei dischi concatenati).
Svantaggi: Impossibile montare dischi hot-spare (sostituzione disco a caldo, senza spegnere il server), affidabilita' minore di un
disco singolo (supposto che i singoli dischi abbiano lo stesso mean time to failure (MTTF) T, un sistema RAID-0 con n dischi avra' un MTTF pari
a T/n), non e' fault tolerant.
RAID 1 (Mirroring)
Il sistema RAID 1 crea una copia esatta (mirror) di tutti i dati su due o piu' dischi. E' utile nei casi in cui la ridondanza e' piu' importante
che usare tutti i dischi alla loro massima capacita': infatti il sistema puo' avere una capacita' massima pari a quella del disco piu' piccolo.
In un sistema ideale, formato da due dischi, l'affidabilita' aumenta di un fattore due rispetto al sistema a disco singolo, ma e' possibile avere
piu' di una copia dei dischi.
Poiche' ogni disco puo' essere gestito autonomamente nel caso l'altro si guasti, l'affidabilita' aumenta linearmente al numero di dischi presenti.
RAID-1 aumenta anche le prestazioni in lettura, visto che molte implementazioni possono leggere da un disco mentre l'altro e' occupato.
Una pratica comune e' di creare un mirror extra di un disco (detto anche Business Continuance Volume o BCV) che puo' essere diviso dal sistema
RAID originario ed essere usato in maniera indipendente. In alcune implementazioni, questi mirror aggiuntivi possono essere divisi e aggiunti
in maniera incrementale, invece di richiedere una ricostruzione completa del RAID.
Vantaggi: affidabilita' che aumenta linearmente con i mirror implementati, fault tolerance, lettura legata al disco piu' veloce della
struttura RAID.
Svantaggi: overhead legato al mirror, bassa scalabilita', alto costo (vengono utilizzati piu' dischi ma se ne sfrutta esclusivamente uno),
scrittura legata al disco piu' lento della struttura RAID.
RAID 2 (Bit Level Striping)
Un sistema RAID 2 divide i dati al livello di bit (invece che di blocco) e usa un codice di Hamming per la correzione d'errore che permette di
correggere errori su singoli bit e di rilevare errori doppi. Questi dischi sono sincronizzati dal controllore, in modo tale che la testina di
ciascun disco sia nella stessa posizione in ogni disco.
Questo sistema si rivela molto efficiente in ambienti in cui si verificano numerosi errori di lettura o scrittura, ma in ambienti piu' prestanti,
data l'elevata affidabilita' dei dischi, il RAID 2 non viene utilizzato. Oggi il RAID 2 viene infatti considerato obsoleto.
RAID 3 (Byte Level Striping with Dedicated Parity Disk)
Un sistema RAID 3 usa una divisione al livello di byte con un disco dedicato alla parita'. Il RAID-3 e' estremamente raro nella pratica.
Uno degli effetti collaterali del RAID-3 e' che non puo' eseguire richieste multiple simultaneamente. Questo perche' ogni singolo blocco di dati
ha la propria definizione diffusa tra tutti i dischi del RAID e risiedera' nella stessa locazione, cosi' ogni operazione di I/O richiede di usare
tutti i dischi.
Nell'esempio accanto, una richiesta per il blocco A richiedera' di cercare attraverso tutti i dischi. Una richiesta simultanea per il
blocco B rimarra' invece in attesa.
RAID 4 (Block Level Striping with Dedicated Parity Disk)
Il sistema RAID 4 usa una divisione a livello di blocchi con un disco dedicato alla parita'. Il RAID-4 assomiglia molto al RAID-3 con l'eccezione
che divide i dati al livello di blocchi invece che al livello di byte.
Questo permette ad ogni disco appartenente al sistema di operare in maniera indipendente quando e' richiesto un singolo blocco.
Se il controllore del disco lo permette, un sistema RAID-4 puo' servire diverse richieste di lettura contemporaneamente. In lettura la capacita'
di trasferimento e' paragonabile al RAID 0, la scrittura e' penalizzata (read-modify-write).
Nell'esempio accanto, una richiesta al blocco A1 potrebbe essere evasa dal disco 1. Una richiesta simultanea al blocco B1 dovrebbe aspettare,
ma una richiesta al blocco B2 potrebbe essere servita allo stesso momento.
Vantaggi: Fault tolerant, read veloci grazie al parallelismo della struttura, possibilita' di inserire dischi hot-spare.
Svantaggi: Il disco utilizzato per la parita' puo' costituire il collo di bottiglia del sistema, scrittura lenta a causa della modifica
e del calcolo della parita' (4 accessi a disco per ogni operazione I/O).
RAID 5 (Distributed Parity)
Un sistema RAID 5 usa una suddivisione dei dati a livello di blocco, distribuendo i dati di parita' uniformemente tra tutti i dischi che lo
compongono.
E' una delle implementazioni piu' popolari, sia in software, sia in hardware, dove praticamente ogni dispositivo integrato di storage dispone
del RAID-5 tra le sue opzioni.
Nell'esempio sottostante, una richiesta al blocco A1 potrebbe essere evasa dal disco 1. Una simultanea richiesta per il blocco B1 dovrebbe
aspettare, ma una richiesta simultanea per il blocco B2 potrebbe essere evasa in contemporanea.
Ogni volta che un blocco di dati (chiamato delle volte chunk) deve essere scritto nel sistema di dischi, un blocco di parita' viene generato
all'interno della stripe.
(Un blocco e' spesso composto da molti settori di disco, delle volte anche 256. Una serie di blocchi consecutivi e' chiamato stripe).
Se un altro blocco, o qualche porzione dello stesso blocco, e' scritta nella stessa stripe, il blocco di parita' viene ricalcolato e riscritto.
Il disco usato per memorizzare le parita' viene modificato tra una stripe e la successiva; in questo modo si riescono a distribuire i blocchi
di parita'.
Bisogna notare che il blocco di parita' non viene letto quando si leggono i dati da disco, visto che sarebbero un sovraccarico non necessario
e diminuirebbe le prestazioni.
Il blocco di parita' e' letto, invece, quando la lettura di un settore da' un errore CRC. In questo caso, il settore nella stessa posizione
relativa nei blocchi di dati rimanenti della stripe, insieme al blocco di parita', vengono usati per ricostruire il blocco mancante.
In questo modo l'errore di CRC viene nascosto al computer chiamante.
Nella stessa maniera, se un disco dovesse danneggiarsi all'interno del sistema, i blocchi di parita' dei dischi rimanenti sono combinati
matematicamente al volo con i blocchi dati rimasti per ricostruire i dati del disco guasto.
Questa procedura viene chiamata di solito Interim Data Recovery Mode. Il computer principale non e' messo al corrente che un disco si e'
danneggiato.
Le letture e scritture verso il sistema di dischi avvengono tranquillamente come prima, sebbene con qualche calo di prestazioni.
In un sistema RAID 5 che ha un solo blocco di parita' per stripe, la rottura di un secondo disco comporta la perdita di tutti i dati presenti
nel sistema.
Il numero massimo di dischi e' teoricamente illimitato, ma una pratica comune e' di mantenere il numero massimo di dischi a 14 o meno per
le implementazioni che hanno solo un blocco di parita' per stripe. Le ragioni per questo limite sono che la probabilita' che due dischi del
sistema si rompano in successione
cresce con il crescere del numero di dischi. Quando il numero di dischi in un sistema RAID-5 cresce, il MTBF del sistema nel suo complesso puo'
persino diventare minore di quello di un singolo disco.
Questo succede quando la probabilita' che si rompa un secondo disco degli (N-1) rimanenti, tra il tempo di accorgersi, sostituire e ricreare
il primo disco guasto, diventi maggiore della probabilita' che un singolo disco si guasti.
Bisogna ricordare che l'aggregazione di piu' dischi in spazi ridotti causa un aumentare della temperatura ed espone quest'ultimi a maggiori
vibrazioni, influendo quindi sulla tolleranza agli errori, aumentando il rischio di failures e rischiando di ridurne il ciclo di vita.
Inoltre, i dischi di uno stesso gruppo comprati nello stesso periodo potrebbero raggiungere la fine della loro vita insieme, abbassando in
maniera significativa il MTBF del sistema. e' buona norma, normalmente seguita dai produttori di server, inserire in RAID dischi identici
ma provenienti da partite differenti, ovvero con numeri di serie e/o date e luogo di produzione distinti e lontani.
E' semplicemente falsa e - come abbiamo visto - anche controproducente l'affermazione, che spesso si trova in alcune aste online o su alcuni
mercatini, che vorrebbe una coppia di dischi con numeri di serie contigui come perfettamente adatta all'utilizzo in RAID.
Nelle implementazioni con piu' di 14 dischi, o in situazioni dove e' necessaria grande ridondanza dei dati, viene usata spesso una implementazione
RAID 5 con doppia parita' (detta anche RAID 6), che riesce a gestire il guasto contemporaneo di due dischi.
Vantaggi: la parita' e' distribuita e quindi non esiste il problema del disco collo di bottiglia come nel RAID 4, le scritture sono piu' veloci
rispetto allo stesso RAID 4, perche' il disco che nel RAID 4 e' dedicato alla parita' ora puo' essere utilizzato per le letture parallele.
Svantaggi: scritture lente a causa della modifica e del calcolo della parita' (4 accessi a disco per ogni operazione I/O).
RAID 6 (Distributed Double Parity)
Un sistema RAID 6 usa una divisione a livello di blocchi con i dati di parità distribuiti due volte tra tutti i dischi. Non era presente tra i livelli
RAID originari.
Nel RAID-6, il blocco di parita' viene generato e distribuito tra due stripe di parità , su due dischi separati, usando differenti stripe di parita' nelle
due direzioni.
Il RAID-6 e' piu' ridondante del RAID-5, ma e' molto inefficiente quando viene usato in un numero limitato di dischi. Vedi la doppia parita', spiegata di
seguito, per una implementazione ancora più ridondante.
RAID 0+1
RAID 1+0
RAID 7
Il sistema RAID 7 e' un marchio registrato della Storage Computer Corporation. Aggiunge un sistema di caching al RAID-3 o RAID-4 per
aumentare le prestazioni.
da http://it.wikipedia.org/wiki/RAID
RAID 0 (Striping)
Il sistema RAID 0 divide i dati equamente tra due o piu' dischi con nessuna informazione di parita' o ridondanza (operazione detta di
striping).
Bisogna notare che il RAID-0 non era presente tra i livelli RAID originari, e che non e' ridondante.
RAID-0 e' usato generalmente per aumentare le prestazioni di un sistema, anche se e' molto utile per creare un piccolo numero di grandi dischi
virtuali da un grande numero di piccoli dischi fisici.
Sebbene il RAID-0 non sia indicato tra i livelli RAID originari, in un sistema ideale di tipo RAID-0 le operazioni di I/O si dividerebbero in
blocchi di dimensioni uguali e si applicherebbero equamente su tutti i dischi.
Le implementazioni di sistemi RAID-0 su piu' di due dischi sono possibili, ma l'affidabilita' di un dato sistema RAID-0 e' uguale all'affidabilita'
media dei dischi diviso per il numero di dischi presenti. Quindi l'affidabilita', misurata come tempo medio tra due guasti (MTBF), e' inversamente
proporzionale al numero degli elementi; cioe' un sistema di due dischi e' affidabile la meta' di un disco solo.
La ragione per la quale questo succede è che il file system e' diviso tra tutti i dischi.
Quando un drive si guasta, il file system non puo' gestire una perdita di dati cosi' grande visto che i dati sono divisi tra tutti i dischi.
I dati possono essere spesso recuperati con qualche strumento, anche se saranno sicuramente incompleti e danneggiati.
RAID-0 e' molto utile per creare grandi server NFS in una sola posizione, nei casi nei quali montare molti dischi e' dispendioso o impossibile
e la ridondanza e' irrilevante.
Si usa anche quando il numero di dischi sia limitato dal sistema operativo. In Microsoft Windows, il numero delle lettere dei dischi e' limitato
a 128, cosi' il RAID-0 e' un modo molto diffuso per usare un numero maggiore di dischi. Comunque, siccome non c'e' ridondanza, i dati sono
condivisi tra i dischi e i dischi non possono essere sostituiti visto che sono tutti dipendenti tra di loro.
Questo tipo di progettazione non e' in realta' un vero e proprio RAID, in quanto non c'e' alcuna ridondanza
Vantaggi: costo economico di implementazione basso, alte prestazioni in scrittura e lettura (grazie al parallelismo delle operazioni I/O
dei dischi concatenati).
Svantaggi: Impossibile montare dischi hot-spare (sostituzione disco a caldo, senza spegnere il server), affidabilita' minore di un
disco singolo (supposto che i singoli dischi abbiano lo stesso mean time to failure (MTTF) T, un sistema RAID-0 con n dischi avra' un MTTF pari
a T/n), non e' fault tolerant.
RAID 1 (Mirroring)
Il sistema RAID 1 crea una copia esatta (mirror) di tutti i dati su due o piu' dischi. E' utile nei casi in cui la ridondanza e' piu' importante
che usare tutti i dischi alla loro massima capacita': infatti il sistema puo' avere una capacita' massima pari a quella del disco piu' piccolo.
In un sistema ideale, formato da due dischi, l'affidabilita' aumenta di un fattore due rispetto al sistema a disco singolo, ma e' possibile avere
piu' di una copia dei dischi.
Poiche' ogni disco puo' essere gestito autonomamente nel caso l'altro si guasti, l'affidabilita' aumenta linearmente al numero di dischi presenti.
RAID-1 aumenta anche le prestazioni in lettura, visto che molte implementazioni possono leggere da un disco mentre l'altro e' occupato.
Una pratica comune e' di creare un mirror extra di un disco (detto anche Business Continuance Volume o BCV) che puo' essere diviso dal sistema
RAID originario ed essere usato in maniera indipendente. In alcune implementazioni, questi mirror aggiuntivi possono essere divisi e aggiunti
in maniera incrementale, invece di richiedere una ricostruzione completa del RAID.
Vantaggi: affidabilita' che aumenta linearmente con i mirror implementati, fault tolerance, lettura legata al disco piu' veloce della
struttura RAID.
Svantaggi: overhead legato al mirror, bassa scalabilita', alto costo (vengono utilizzati piu' dischi ma se ne sfrutta esclusivamente uno),
scrittura legata al disco piu' lento della struttura RAID.
RAID 2 (Bit Level Striping)
Un sistema RAID 2 divide i dati al livello di bit (invece che di blocco) e usa un codice di Hamming per la correzione d'errore che permette di
correggere errori su singoli bit e di rilevare errori doppi. Questi dischi sono sincronizzati dal controllore, in modo tale che la testina di
ciascun disco sia nella stessa posizione in ogni disco.
Questo sistema si rivela molto efficiente in ambienti in cui si verificano numerosi errori di lettura o scrittura, ma in ambienti piu' prestanti,
data l'elevata affidabilita' dei dischi, il RAID 2 non viene utilizzato. Oggi il RAID 2 viene infatti considerato obsoleto.
RAID 3 (Byte Level Striping with Dedicated Parity Disk)
Un sistema RAID 3 usa una divisione al livello di byte con un disco dedicato alla parita'. Il RAID-3 e' estremamente raro nella pratica.
Uno degli effetti collaterali del RAID-3 e' che non puo' eseguire richieste multiple simultaneamente. Questo perche' ogni singolo blocco di dati
ha la propria definizione diffusa tra tutti i dischi del RAID e risiedera' nella stessa locazione, cosi' ogni operazione di I/O richiede di usare
tutti i dischi.
Nell'esempio accanto, una richiesta per il blocco A richiedera' di cercare attraverso tutti i dischi. Una richiesta simultanea per il
blocco B rimarra' invece in attesa.
RAID 4 (Block Level Striping with Dedicated Parity Disk)
Il sistema RAID 4 usa una divisione a livello di blocchi con un disco dedicato alla parita'. Il RAID-4 assomiglia molto al RAID-3 con l'eccezione
che divide i dati al livello di blocchi invece che al livello di byte.
Questo permette ad ogni disco appartenente al sistema di operare in maniera indipendente quando e' richiesto un singolo blocco.
Se il controllore del disco lo permette, un sistema RAID-4 puo' servire diverse richieste di lettura contemporaneamente. In lettura la capacita'
di trasferimento e' paragonabile al RAID 0, la scrittura e' penalizzata (read-modify-write).
Nell'esempio accanto, una richiesta al blocco A1 potrebbe essere evasa dal disco 1. Una richiesta simultanea al blocco B1 dovrebbe aspettare,
ma una richiesta al blocco B2 potrebbe essere servita allo stesso momento.
Vantaggi: Fault tolerant, read veloci grazie al parallelismo della struttura, possibilita' di inserire dischi hot-spare.
Svantaggi: Il disco utilizzato per la parita' puo' costituire il collo di bottiglia del sistema, scrittura lenta a causa della modifica
e del calcolo della parita' (4 accessi a disco per ogni operazione I/O).
RAID 5 (Distributed Parity)
Un sistema RAID 5 usa una suddivisione dei dati a livello di blocco, distribuendo i dati di parita' uniformemente tra tutti i dischi che lo
compongono.
E' una delle implementazioni piu' popolari, sia in software, sia in hardware, dove praticamente ogni dispositivo integrato di storage dispone
del RAID-5 tra le sue opzioni.
Nell'esempio sottostante, una richiesta al blocco A1 potrebbe essere evasa dal disco 1. Una simultanea richiesta per il blocco B1 dovrebbe
aspettare, ma una richiesta simultanea per il blocco B2 potrebbe essere evasa in contemporanea.
Ogni volta che un blocco di dati (chiamato delle volte chunk) deve essere scritto nel sistema di dischi, un blocco di parita' viene generato
all'interno della stripe.
(Un blocco e' spesso composto da molti settori di disco, delle volte anche 256. Una serie di blocchi consecutivi e' chiamato stripe).
Se un altro blocco, o qualche porzione dello stesso blocco, e' scritta nella stessa stripe, il blocco di parita' viene ricalcolato e riscritto.
Il disco usato per memorizzare le parita' viene modificato tra una stripe e la successiva; in questo modo si riescono a distribuire i blocchi
di parita'.
Bisogna notare che il blocco di parita' non viene letto quando si leggono i dati da disco, visto che sarebbero un sovraccarico non necessario
e diminuirebbe le prestazioni.
Il blocco di parita' e' letto, invece, quando la lettura di un settore da' un errore CRC. In questo caso, il settore nella stessa posizione
relativa nei blocchi di dati rimanenti della stripe, insieme al blocco di parita', vengono usati per ricostruire il blocco mancante.
In questo modo l'errore di CRC viene nascosto al computer chiamante.
Nella stessa maniera, se un disco dovesse danneggiarsi all'interno del sistema, i blocchi di parita' dei dischi rimanenti sono combinati
matematicamente al volo con i blocchi dati rimasti per ricostruire i dati del disco guasto.
Questa procedura viene chiamata di solito Interim Data Recovery Mode. Il computer principale non e' messo al corrente che un disco si e'
danneggiato.
Le letture e scritture verso il sistema di dischi avvengono tranquillamente come prima, sebbene con qualche calo di prestazioni.
In un sistema RAID 5 che ha un solo blocco di parita' per stripe, la rottura di un secondo disco comporta la perdita di tutti i dati presenti
nel sistema.
Il numero massimo di dischi e' teoricamente illimitato, ma una pratica comune e' di mantenere il numero massimo di dischi a 14 o meno per
le implementazioni che hanno solo un blocco di parita' per stripe. Le ragioni per questo limite sono che la probabilita' che due dischi del
sistema si rompano in successione
cresce con il crescere del numero di dischi. Quando il numero di dischi in un sistema RAID-5 cresce, il MTBF del sistema nel suo complesso puo'
persino diventare minore di quello di un singolo disco.
Questo succede quando la probabilita' che si rompa un secondo disco degli (N-1) rimanenti, tra il tempo di accorgersi, sostituire e ricreare
il primo disco guasto, diventi maggiore della probabilita' che un singolo disco si guasti.
Bisogna ricordare che l'aggregazione di piu' dischi in spazi ridotti causa un aumentare della temperatura ed espone quest'ultimi a maggiori
vibrazioni, influendo quindi sulla tolleranza agli errori, aumentando il rischio di failures e rischiando di ridurne il ciclo di vita.
Inoltre, i dischi di uno stesso gruppo comprati nello stesso periodo potrebbero raggiungere la fine della loro vita insieme, abbassando in
maniera significativa il MTBF del sistema. e' buona norma, normalmente seguita dai produttori di server, inserire in RAID dischi identici
ma provenienti da partite differenti, ovvero con numeri di serie e/o date e luogo di produzione distinti e lontani.
E' semplicemente falsa e - come abbiamo visto - anche controproducente l'affermazione, che spesso si trova in alcune aste online o su alcuni
mercatini, che vorrebbe una coppia di dischi con numeri di serie contigui come perfettamente adatta all'utilizzo in RAID.
Nelle implementazioni con piu' di 14 dischi, o in situazioni dove e' necessaria grande ridondanza dei dati, viene usata spesso una implementazione
RAID 5 con doppia parita' (detta anche RAID 6), che riesce a gestire il guasto contemporaneo di due dischi.
Vantaggi: la parita' e' distribuita e quindi non esiste il problema del disco collo di bottiglia come nel RAID 4, le scritture sono piu' veloci
rispetto allo stesso RAID 4, perche' il disco che nel RAID 4 e' dedicato alla parita' ora puo' essere utilizzato per le letture parallele.
Svantaggi: scritture lente a causa della modifica e del calcolo della parita' (4 accessi a disco per ogni operazione I/O).
RAID 6 (Distributed Double Parity)
Un sistema RAID 6 usa una divisione a livello di blocchi con i dati di parità distribuiti due volte tra tutti i dischi. Non era presente tra i livelli
RAID originari.
Nel RAID-6, il blocco di parita' viene generato e distribuito tra due stripe di parità , su due dischi separati, usando differenti stripe di parita' nelle
due direzioni.
Il RAID-6 e' piu' ridondante del RAID-5, ma e' molto inefficiente quando viene usato in un numero limitato di dischi. Vedi la doppia parita', spiegata di
seguito, per una implementazione ancora più ridondante.
RAID 0+1
RAID 1+0
RAID 7
Il sistema RAID 7 e' un marchio registrato della Storage Computer Corporation. Aggiunge un sistema di caching al RAID-3 o RAID-4 per
aumentare le prestazioni.
da http://it.wikipedia.org/wiki/RAID
Rete, risoluzione problemi (ping, tracert, telnet, arp, nslookup
Ecco i comandi che usiamo quando si presenta un problema sulla nostra rete, generalmente parte tutto da un collega/utente che segnala un host
(server o client) o un intera rete remota con dei problemi di raggiungibilità o di performance.
PING
E un comando utilizzato per conoscere la presenza e la raggiungibilità di un host connesso sulla rete.
SINTASSI: ping [opzioni] destinazione
 Il parametro destinazione può essere un indirizzo IP o un nome DNS. I parametri opzioni più utili sono:
-t esegue il ping dellhost specificato finché non viene interrotto.
Utile per verificare la raggiungibilità di un host che abbiamo riavviato da remoto e verificare se e quando torna up; avere una statistica dei
pacchetti ricevuti e persi in un determinato periodo di tempo in caso di problemi sulla rete.
-l NumByte specifica una dimensioni differente del buffer di invio. E utile per verificare se con pacchetti
di dimensione maggiore di 32 byte (dimesione di default) si hanno dei tempi di risposta TTL troppo alti (latenza) o nessuna risposta.
Questo potrebbe essere un sintomo di una rete troppo lenta perchè troppo trafficata o degradata
In Output genera una statistica che indica il numero di pacchetti trasmessi, ricevuti e per quelli persi indica anche una percentuale.
Esprime anche il tempo minimo, massimo e medio che ha impiegato il pacchetto a fare il percorso di andata e ritorno dalla sorgente
(lhost dal quale si esegue il comando) alla destinazione (lhost che si vuole raggiungere)
Attenzione non sempre un host che non risponde al ping non è raggiugibile! Ad esempio se protetto da un Firewall (HW/SW) lhost potrebbe
non ricevere affatto questo pacchetti e restituire delle statistiche che non servono a molto.
In caso di host non raggiungibile si può continuare lanalisi utilizzando il comando tracert
TRACERT
E un comando che traccia linstradamento dallhost sorgente (lhost sul quale abbiamo lanciato il comando) verso lhost di destinazione, segnalando
il tempo impiegato per raggiungere ciascun gateway (apparato di rete tipicamente router) intermedio tra la sorgente e la destinazione.
Il primo hop che verrà visualizzato sarà e deve essere corrispondente al default gateway della rete dellhost sorgente
SINTASSI: tracert [opzioni] destinazione
Il parametro destinazione può essere un indirizzo IP o un nome DNS. I parametri opzioni più utili sono:
-t esegue il ping dellhost specificato finché non viene interrotto.
Utile per verificare la raggiungibilità di un host che abbiamo riavviato da remoto e verificare se e quando torna up; avere una statistica dei
pacchetti ricevuti e persi in un determinato periodo di tempo in caso di problemi sulla rete.
-l NumByte specifica una dimensioni differente del buffer di invio. E utile per verificare se con pacchetti
di dimensione maggiore di 32 byte (dimesione di default) si hanno dei tempi di risposta TTL troppo alti (latenza) o nessuna risposta.
Questo potrebbe essere un sintomo di una rete troppo lenta perchè troppo trafficata o degradata
In Output genera una statistica che indica il numero di pacchetti trasmessi, ricevuti e per quelli persi indica anche una percentuale.
Esprime anche il tempo minimo, massimo e medio che ha impiegato il pacchetto a fare il percorso di andata e ritorno dalla sorgente
(lhost dal quale si esegue il comando) alla destinazione (lhost che si vuole raggiungere)
Attenzione non sempre un host che non risponde al ping non è raggiugibile! Ad esempio se protetto da un Firewall (HW/SW) lhost potrebbe
non ricevere affatto questo pacchetti e restituire delle statistiche che non servono a molto.
In caso di host non raggiungibile si può continuare lanalisi utilizzando il comando tracert
TRACERT
E un comando che traccia linstradamento dallhost sorgente (lhost sul quale abbiamo lanciato il comando) verso lhost di destinazione, segnalando
il tempo impiegato per raggiungere ciascun gateway (apparato di rete tipicamente router) intermedio tra la sorgente e la destinazione.
Il primo hop che verrà visualizzato sarà e deve essere corrispondente al default gateway della rete dellhost sorgente
SINTASSI: tracert [opzioni] destinazione
 Il parametro destinazione può essere un indirizzo IP o un nome DNS
-d il parametro opzione più utile è il -d perchè in questo modo non vengono risolti gli indirizzi IP in
nome host per cui viene restituito un risultato molto più velocemente.
-h di default linstradamento viene rilevato su un massimo di 30 hop per raggiungere la destinazione,
se la destinazione è più lontana si deve incrementare il numero di hope con lopzione -h
In Output tramite questo comando riusciamo a capire se il nostro pacchetto sta prendendo seguendo il percorso giusto per arrivare a
destnazione e in caso di mancato instradamento si può iniziare la diagnostica partendo dallhost sul quale viene perso il pacchetto.
Attenzione durante il percorso il pacchetto potrebbe attraversare un Firewall che blocca questi pacchetti restituendo così solo un
risultato parziale e magari non utile per la nostra diagnostica.
Se accade questo si può continuare lanalisi sullhost utilizzando il comando telnet, utile per aprire una sessione sullhost di destinazione.
TELNET
Serve per aprire una sessione sullhost di destinazione collegandosi ad ad una porta TCP di un sistema su cui "ascolta" un particolare server.
SINTASSI: telnet destinazione [porta]
Il parametro destinazione può essere un indirizzo IP o un nome DNS
-d il parametro opzione più utile è il -d perchè in questo modo non vengono risolti gli indirizzi IP in
nome host per cui viene restituito un risultato molto più velocemente.
-h di default linstradamento viene rilevato su un massimo di 30 hop per raggiungere la destinazione,
se la destinazione è più lontana si deve incrementare il numero di hope con lopzione -h
In Output tramite questo comando riusciamo a capire se il nostro pacchetto sta prendendo seguendo il percorso giusto per arrivare a
destnazione e in caso di mancato instradamento si può iniziare la diagnostica partendo dallhost sul quale viene perso il pacchetto.
Attenzione durante il percorso il pacchetto potrebbe attraversare un Firewall che blocca questi pacchetti restituendo così solo un
risultato parziale e magari non utile per la nostra diagnostica.
Se accade questo si può continuare lanalisi sullhost utilizzando il comando telnet, utile per aprire una sessione sullhost di destinazione.
TELNET
Serve per aprire una sessione sullhost di destinazione collegandosi ad ad una porta TCP di un sistema su cui "ascolta" un particolare server.
SINTASSI: telnet destinazione [porta]
 Di default la porta se non specificata è la 23 e se host risponde lo farà tramite una shell proponendoti magari una login per laccesso remoto
(come succede ad esempio quando accediamo ad un router Cisco).
Molto spesso è utilie utilizzare il comando su altre porte ossia aprire una sessione sulla porta dellhost che sappiamo dovrebbe essere in ascolto:
Ad esepio utilizziamo la porta:
21 se sappiamo che lhost dovrebbe fornire un servizio di ftp
22 ssh se dobbiamo collegarci a remoto su una shell remota di un server
25 smtp se lhost ha un servizio di invio e ricezione posta
80 http se lhost è un server web
etc
In Output se il comando telnet va a buon fine la sessione sullhost/server resta appesa ed risulterà possibile, usando i comandi corretti
interrogare il server.
Se il telnet è sulla porta 80 si dovranno usare comandi HTTP, se il collegamento è sulla porta 25 usiamo i comandi SMTP, sulla porta 110 i comandi
POP3 etc
ARP
Consente di visualizzare la tabella di conversione da indirizzi IP a indirizzi fisici MAC Address sullhost dal quale si sta eseguendo il comando
SINTASSI: arp [opzioni]
Di default la porta se non specificata è la 23 e se host risponde lo farà tramite una shell proponendoti magari una login per laccesso remoto
(come succede ad esempio quando accediamo ad un router Cisco).
Molto spesso è utilie utilizzare il comando su altre porte ossia aprire una sessione sulla porta dellhost che sappiamo dovrebbe essere in ascolto:
Ad esepio utilizziamo la porta:
21 se sappiamo che lhost dovrebbe fornire un servizio di ftp
22 ssh se dobbiamo collegarci a remoto su una shell remota di un server
25 smtp se lhost ha un servizio di invio e ricezione posta
80 http se lhost è un server web
etc
In Output se il comando telnet va a buon fine la sessione sullhost/server resta appesa ed risulterà possibile, usando i comandi corretti
interrogare il server.
Se il telnet è sulla porta 80 si dovranno usare comandi HTTP, se il collegamento è sulla porta 25 usiamo i comandi SMTP, sulla porta 110 i comandi
POP3 etc
ARP
Consente di visualizzare la tabella di conversione da indirizzi IP a indirizzi fisici MAC Address sullhost dal quale si sta eseguendo il comando
SINTASSI: arp [opzioni]
 -a visualizzazione completa della tabella tabella
Potrebbe risultare utile quando abbiamo il dubbio di avere in rete un host con indirizzo duplcato, andremo in questo caso a verificare se il mac
address dellhost di destinazione corrisponde a quello che troviamo nella tabella arp
NSLOOKUP
E un comando che consente di fare delle interrogazioni ai server DNS
SINTASSI: arp [opzioni]
-a visualizzazione completa della tabella tabella
Potrebbe risultare utile quando abbiamo il dubbio di avere in rete un host con indirizzo duplcato, andremo in questo caso a verificare se il mac
address dellhost di destinazione corrisponde a quello che troviamo nella tabella arp
NSLOOKUP
E un comando che consente di fare delle interrogazioni ai server DNS
SINTASSI: arp [opzioni]
 Di default se non specificato linterrogazione viene fatta sul server DNS specificato nella connessione di rete dellhost sul quale abbiamo
lanciato il comando.
Se abbiamo la necessità di cambiare DNS dobbiamo utilizzare il parametro server [ip o nome server dns].
Con questo comando possiamo fare delle query ai DNS nel caso, ad esempio, abbiamo una mancata risoluzione di un IP o un nome DNS,
o dubitiamo che quella risoluzione sia corretta, o cerchiamo informazioni aggiuntive su un dominio internet.
Tipo di query
set q=any
www.libero.it
restituisce lip e il nome del server www del dominio libero.it
set q=ns
libero.it
restituisce lip e il nome dei server dns autoritativi per il dominio libero.it
set q=mx
restituisce lip e il nome dei server mail che ricevono posta indirizzata al dominio @libero.it
Di default se non specificato linterrogazione viene fatta sul server DNS specificato nella connessione di rete dellhost sul quale abbiamo
lanciato il comando.
Se abbiamo la necessità di cambiare DNS dobbiamo utilizzare il parametro server [ip o nome server dns].
Con questo comando possiamo fare delle query ai DNS nel caso, ad esempio, abbiamo una mancata risoluzione di un IP o un nome DNS,
o dubitiamo che quella risoluzione sia corretta, o cerchiamo informazioni aggiuntive su un dominio internet.
Tipo di query
set q=any
www.libero.it
restituisce lip e il nome del server www del dominio libero.it
set q=ns
libero.it
restituisce lip e il nome dei server dns autoritativi per il dominio libero.it
set q=mx
restituisce lip e il nome dei server mail che ricevono posta indirizzata al dominio @libero.it
 Questultimo comando potrebbe essere utile ad esempio in caso non si riesce più ad inviare posta al dominio specificato, una volta identificato
tramite query lMX, ossia il mail server del dominio, si può fare un telnet con destinazione il mail server sulla porta 25 e tramite i comandi
SMTP, inviare una mail al destinatario a cui non riusciamo ad inviare posta.
Questultimo comando potrebbe essere utile ad esempio in caso non si riesce più ad inviare posta al dominio specificato, una volta identificato
tramite query lMX, ossia il mail server del dominio, si può fare un telnet con destinazione il mail server sulla porta 25 e tramite i comandi
SMTP, inviare una mail al destinatario a cui non riusciamo ad inviare posta.

|